


What is AI anyway, and why should I care?

Introduction
While eating dinner with my cousin several months ago, she mentioned that a tech worker had come to her office to demonstrate the uses of ChatGPT and chaos had ensued. The worker had shown several examples of ChatGPT performing some of their job functions, and her coworkers had become upset thinking they were all about to lose their jobs. As someone with a degree in machine learning who works in a research environment, I was well aware of the limitations of AI, but I realized I was not equipped to explain them all on-the-spot without getting deep into the weeds. That night, I tried to look for articles to explain what machine learning was and what some of the problems associated with it were. However, none of the articles I could find had the level of detail I wanted - some were too technical for a non-engineering audience, some were too high-level - they explained what a neural network was, but not how it works- and some only discussed ethics, without a technical background as to why these problems existed.
As AI becomes more relevant to our day-to-day lives, it is critical that we all understand it. Lawmakers, philosophers, and ethicists need to work with scientists and engineers to develop a new ethical framework and set of laws to govern AI, and in order to do that, they need to understand what AI is, how it works, and the different choices that can be made. In the meantime, the general public needs to have a basic understanding of what AI is so they can understand how it can affect them and be prepared for new products that are coming out. My hope is that this essay can present the background of what AI really means using a high-school level understanding of math, as well as context on the decisions that engineers make when working with AI and how that can affect the results.
Throughout this article, I am going to be using an example immortalized in HBO’s Silicon Valley - an app that can identify if there is a hot dog in a picture.
Definitions
In popular culture, several related terms are often used interchangeably when discussing machine learning. However, each means subtly different things.
Artificial Intelligence, or AI, refers to the ability of a machine to learn and generalize. This is the widest category, and can refer to programs as simple as “If there is red in the image, then it contains a hot dog”. Sometimes companies will use this term to market more traditional approaches because people think AI and ML are in right now.
Machine Learning, or ML, is a subset of AI that teaches a program to be able to do something without being told. There are several main types of machine learning:
Supervised Learning- This is a form of machine learning in which you have both labels and data. In our example, this would mean we have a data set of images and corresponding labels that say “hot dog” or “not a hot dog”. It is the most common for classification approaches like our example, so the rest of the article will discuss a supervised learning approach.
Unsupervised Learning - This is a form of machine learning in which you only have labels. In our case, we would have a data set of pictures, but no information on which contain hot dogs.
Reinforcement Learning - This is a form of machine learning most often used for robotics, in which the program is trying to learn to maximize a reward. This would be awkward to implement for our case.
Neural Networks are a common form of machine learning that attempt to mimic the structures of a human brain through layers of nodes.This is almost always what newspapers mean when they talk about “groundbreaking new AI/ML”. When people say things like “large language model”, or “generative model”, they are referring to types of neural networks. The rest of this article is going to go into neural networks in detail.
Deep Learning is a term for neural networks that are larger than 3 layers.
Neural Network Overview
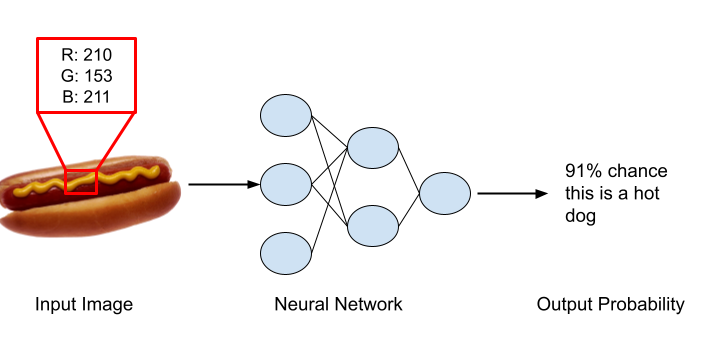
As mentioned above, a neural network attempts to mimic the structure of the human brain through layers of nodes. You can see an example of a very simple, one-layer neural network in the image below. On the left is the input image. We see a hot dog, but the computer sees an array of pixels. Each pixel contains three numbers. These numbers represent the amount of red, blue, and green in the image.

In the middle is the neural network, which in this case is a single node. This node takes in the array of pixels, x, and performs a mathematical operation on them. This can be something as simple as “y = mx + b”, but is usually much more complicated. In our example, x is the pixels that represent the input image, m and b are called weights, and y is our output. We want to figure out if this image contains a hot dog, so for us y represents the percent chance that there is a hot dog in the image. If our neural network has been trained well, this will tell us that there is a high probability that there is a hot dog in the image above, and if we give it a picture of a cat, it will say there is a low probability there is a hot dog. If we add more layers to the network, it will be able to learn more during training, and thus be more confident in its answers. You can see in the image below that this deeper network reports a higher probability that the image is a hot dog when compared to our simple network. These deeper networks will have even more complicated mathematical operations, and different operations correspond to different use cases and frameworks. That is why ChatGPT and DALL-E are both neural networks even though they produce very different outputs.
Training a Neural Network
This is all well and good, but the section above skated over the most difficult part - training the neural network. Training refers to the process of the network learning the weights. In our case, this would be learning the best values for m and b. Often, coming up with the structure of the neural network is easy, and training and preparing the data for training is the part that consumes the most time. In addition, it is the part where most ethical decisions must be made.
An easy way to understand how training a neural network works is to think of it in two-dimensional space, like the image below. Let’s assume that the node in our first, simple network is trying to learn how to decide if an image contains a hot dog based on the amounts of green and red in the image. The network will draw a line, called a “decision boundary”, in between the data. Everything below the line will be classified as “hot dog”, and everything above the line will be “not a hot dog”. We have several example pictures with labels, as shown by the red and green dots. The network wants to learn the values of m and b that will result in the most amount of pictures that contain hot dogs being classified as such, and vice versa. It does this by classifying all the data it has, then comparing it to our labels with a loss function. A loss function says how far away the network’s guess was from the truth. For our example, this could be something as simple as “true label probability - network probability”. After it sees those numbers, it performs calculus to update the m and b values, then runs through the data again. This updating and loss calculation steps are called optimization and backpropagation.

The more data the network has, the better it is at generalizing. For our example, if we only had pictures of hot dogs from Nathan’s, it might not be able to recognize homemade hot dogs, since it has never seen a picture of a homemade hot dog before, and would be unable to tell that that combination of red and green meant “hot dog”. How long you train the network can also affect the ability. If you stop too early, the network might not be able to learn as much as it can. If you stop too late, it can overfit. This is when the network knows the training data so well that it learns patterns that do not exist in the real world. For example, in Chicago, people don’t put ketchup on their hot dogs. If we only give the network pictures of New York hot dogs with ketchup, the network will learn “ketchup equals hot dog”, and will have trouble recognizing Chicago hot dogs as hot dogs.
The Importance of Data Sets
The decisions that engineers make when preparing their data and training their network can dramatically affect the results of the network. This can be explained by thinking about the decision boundary and looking at the figure below. In our original example, the network learned a decision boundary based on the data that was given to it. If we then provide the network with more examples of hot dogs, but these examples contain more red in the images than those in our original data set, the network will learn a different decision boundary. This could result in a different number of false positives or false negatives, and whether this is a positive or negative thing depends on what our end goal is.

The biggest, most obvious choice the engineer must make is the choice of data set. Several factors are important to consider when building a data set. It is essential that the data set covers as many of the expected cases as possible, or else the network will not work as well on real-world data. Lack of diverse training sets contributes to high-profile issues of ML bias, such as facial recognition software being unable to identify darker-skinned people.
Another issue to consider is the engineer’s domain knowledge, or lack thereof. The math going into a typical neural network is much more complicated than our example, and it is impossible for an engineer to understand what is happening at every node. If the engineer has a lack of knowledge about the problem they are trying to solve, they can miss important details in the data set, or have the network learn correlations that are undesirable. This issue can also contribute to bias, such as the discriminatory algorithms banks use to determine mortgage eligibility. Even with domain experts on hand to analyze the data, it can still be difficult to determine if an algorithm is biased.
Finally, it is important to consider the end use case of the algorithm and what the engineer or company would like to reflect. It is here that philosophy and ethics must be considered closely, and in a perfect work this intention would be clearly communicated to the end user. For our hot dog example, imagine we have assembled our data set of beef hot dogs, but then we are told to add in equal numbers of images of BeyondMeat hot dogs. BeyondMeat hot dogs do not make up 50% of the hot dog market, so our model would no longer be reflecting reality. Is this OK? What if we are doing this because we are worried about climate change and we want to influence more people to become vegan? What if we are doing it because BeyondMeat is paying us? It is in this area where ethicists, lawmakers, and scientists should work together to develop laws and codes of conduct that regulate how these decisions are made and how they should be communicated to the end user.
Ethical Considerations
In addition to the design choices engineers must make when training their models, there are also ethical issues to consider. In order for large-scale neural networks to be accurate, they require large amounts of data. Often, it is prohibitively difficult or expensive for a company to create its own data set, so it will look to the Internet. Some data sets are publicly available with dedicated licenses, especially those that are for research or competition purposes. However, in many cases, engineers end up scraping the internet in order to get the data they need. For example, OpenAI trained Chat GPT with “570GB of data obtained from books, webtexts, Wikipedia, articles and other pieces of writing on the internet.” This is an ethical dilemma - while those who chose to put their work on the internet knew it could be used for other purposes, is it really fair for a private company to be making massive amounts of money using data they took from smaller creators without payment, or is that the price we pay for progress? Is it reasonable that a small creator posting on DeviantArt in 2008 would be able to predict that their work would be used in this way in 2023? Does the output of these networks count as new work, or is it simply plagiarism of the training set? This is another area where lawmakers and scientists need to work together to develop a comprehensive framework and body of laws that govern the Internet. Approaches could include adopting the code licensing framework for all things posted on the Internet, or adopting GDPR world-wide.
Another ethical concern with data sets is the labeling of the data. Even in cases where it is easy to acquire raw data, supervised machine learning is much more effective than unsupervised, so labels are desired. It is tedious and time consuming to label these images, and some companies turn to controversial methods of data labeling such as Amazon Mechanical Turk, where labeling is outsourced for a small price. Bias and cultural context can also create issues in the labeling - what if two labellers have a different idea of what constitutes a hot dog?
Conclusion
My hope is that this essay was able to convey what a neural network is and how the choices engineers make when creating them can affect the wider world. My goal in creating this essay is not to preach a single answer - I am an engineer, not a philosopher. I want this essay to provoke thoughts in the reader about what those answers should be, and work to make them happen.